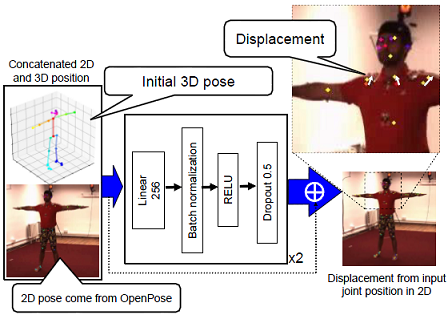
PoseRN: A 2D pose refinement network for bias-free multi-view 3D human pose estimation
We propose a new 2D pose refinement network that learns to predict the human bias in the estimated 2D pose. There are biases in 2D pose estimations that are due to differences between annotations of 2D joint locations based on annotators' perception and those defined by motion capture (MoCap) systems. These biases are crafted into publicly available 2D pose datasets and cannot be removed with existing error reduction approaches. Our proposed pose refinement network allows us to efficiently remove the human bias in the estimated 2D poses and achieve highly accurate multi-view 3D human pose estimation.
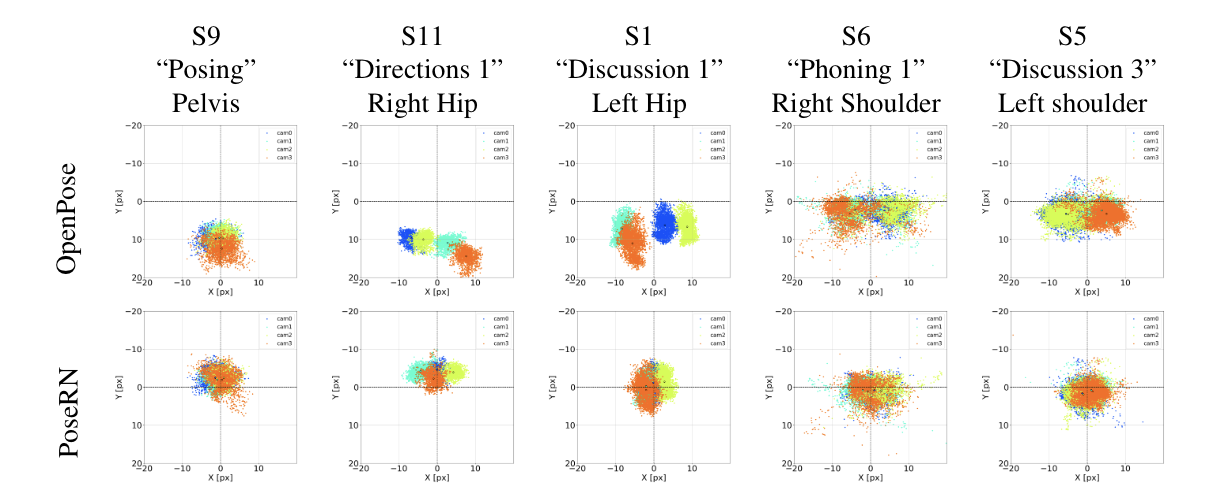
We reason that humans have a similar perception of thehuman body and that the errors made when guessing 2D joint locations tend to be similar for different persons. As a consequence, there is a bias in 2D pose annotation datasets thatdepends on both camera pose and human body pose. Open-Pose joint positions are clearly off from the origin, indicating the presence of the bias. In contrast, PoseRN successfully reduces this bias. The fact that the bias is predictable may inductively support our assumption that the bias comes from the discrepancy in the joint definitions.