| 水中画像の深層学習による画像品質の向上手法 |
AutoEnhancer: Transformer on U-Net Architecture search for Underwater Image Enhancementほとんどの深層学習ベースのアプローチは、このタスクのために異なる構造を導入し、個別のニューラルネットワークを設計して成功していますが、これらのネットワークは通常、デザイナーの知識と経験に依存して検証されます。 この論文では、Neural Architecture Search(NAS)を使用して水中画像の向上のための最適なアーキテクチャを探索し、効果的で軽量な深層ネットワークを取得できるようにします。 ニューラルネットワークの能力を向上させるために、私たちは新しい検索を提案し、畳み込みなどの一般的なオペレータに制限されるのではなく、トランスフォーマを含む検索空間を採用します。さらに、NASをトランスフォーマに適用し、選択可能なトランスフォーマ構造を提案します。 マルチヘッドのセルフアテンションモジュールはオプションのユニットと見なされ、異なるトランスフォーマ構造を導出します。 この変更は、検索空間を拡大し、ネットワークの学習能力を向上させることができます。我々のNASベースの強化ネットワークは、広く使用されているU-Netアーキテクチャを継承しており、エンコーダーとデコーダーの2つのコンポーネントで構成されています。従来のU-Netアーキテクチャとは異なり、元の残差構造や畳み込みブロックは提案されたNASブロックに置き換えられています。これにより、ネットワークは自動的に最適なオペレータを選択し、画像の向上のための堅牢で信頼性のある特徴を学習できます。以下の図は、提案されたNASベースのフレームワークを示しています。低品質の画像が与えられると、RGBおよびLabの2つのカラースペースが提案されたネットワークに入力されます。エンコーダーでは、ダウンサンプリング操作と異なる受容野を使用して、多レベルの特徴が抽出されます。その後、これらの特徴はさらにアップサンプリングされ、デコーダーで最終的な向上画像を復元するために統合されます。 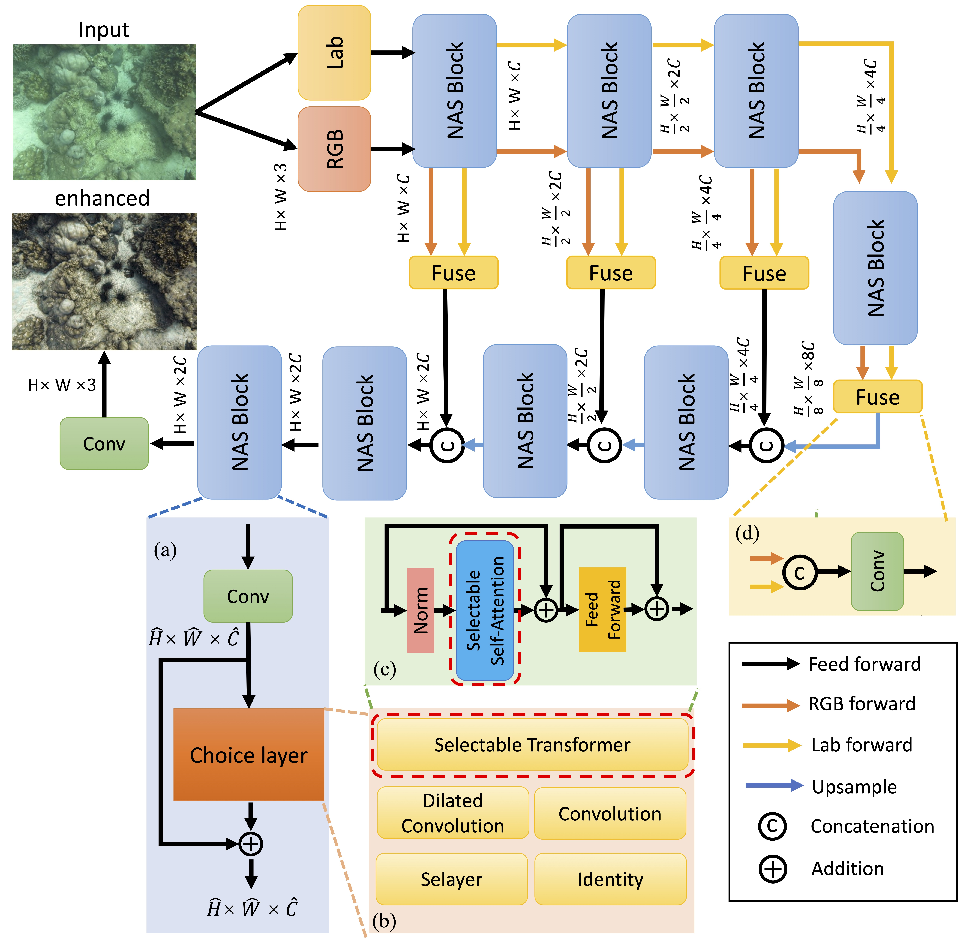
下の図は、提案された方法と水中シーンに関する最新技術との視覚的比較を示しています。船の難破(第1行)は、水中画像が色の歪み、ぼやけ、斑点模様など、さまざまなノイズに苦しむ可能性があることを示しています。以前のアプローチは、一部のノイズを除去し、原本の内容をある程度回復できますが、その向上画像には依然としていくつかの欠点が存在します。たとえば、FUnlEは主要な歪んだ色を除去しますが、左下と右下の隅には取り除けないノイズ領域が残っています。WaterNetとUshapeは元の画像の内容とテクスチャを回復できますが、画像全体の色調が変わります。彼らの向上画像と比較して、私たちの結果は画像の内容を回復するだけでなく、可能な限り色調を保持しています。 
Resources
Data: GoogleDrive(pre-trained model) Publications
Underwater Image Enhancement by Transformer-based Diffusion Model with Non-uniform Sampling for Skip Strategyこの論文では、水中シーンでの拡散モデルを用いた画像の向上アプローチを提案しています。私たちの方法は、水中画像を入力として使用し、条件付きデノイジング拡散確率モデルを適応して、対応する向上画像を生成します。さらに、拡散モデルの逆プロセスの効率を向上させるために、2つの異なる方法を採用しています。まず、ネットワークのイテレーションごとの前進時間を効果的に促進できる軽量なトランスフォーマベースのデノイジングネットワークを提案します。一方、イテレーションの数を減らすためにスキップサンプリング戦略を導入します。さらに、スキップサンプリング戦略に基づいて、時間ステップのシーケンス用に2つの異なる非一様サンプリング方法を提案します。これらの方法はどちらも効果的で、以前の一様サンプリングに対して同じ手法を使用して性能をさらに向上させることができます。最後に、最新の最先端の手法と提案されたアプローチとの間で広く使用されている水中向上データセットの相対評価を行います。実験結果は、私たちのアプローチが競争力のある性能と高い効率の両方を実現できることを証明しています。図に示すように、私たちのフレームワークには主に拡散プロセス、トランスフォーマベースのデノイジングネットワーク、およびチャネルごとの注意モジュールが含まれています。私たちの目的は、低品質の画像を与えることで対応する向上画像を生成することです。これは、不確定な結果を持つ元の拡散モデルを使用しても満足できます。したがって、条件付き拡散モデルを導入します。入力、すなわちノイズのある画像、条件画像、および時間ステップが与えられると、ネットワークはノイジー分布を推定するために使用されます。トレーニングプロセス中、私たちはネットワークを最適化するためにL1損失を使用します。 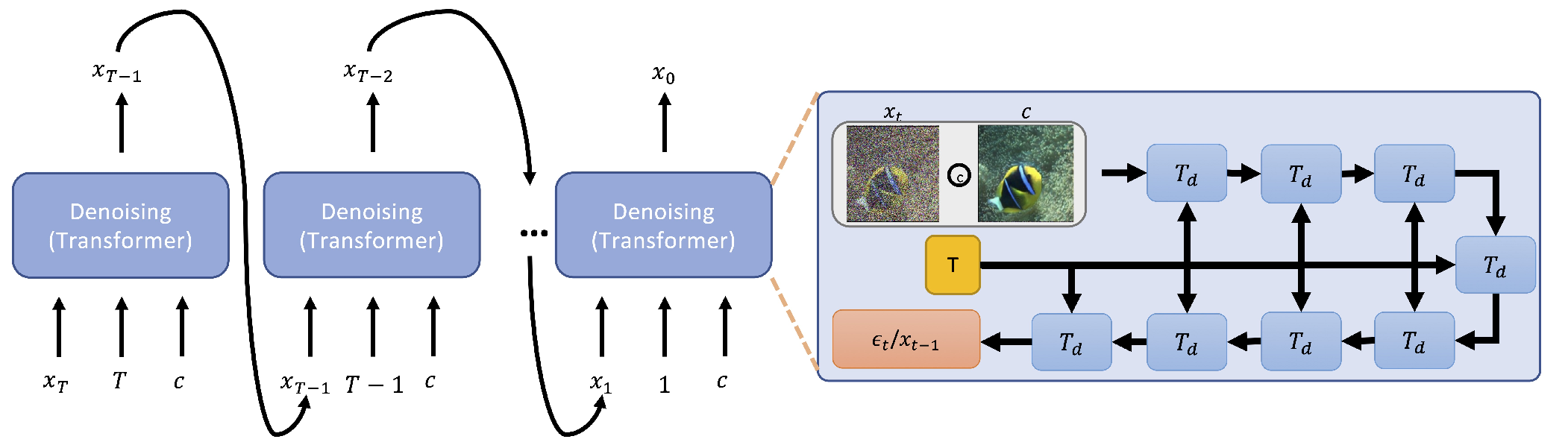
従来の方法では、通常、固定のストライドで均一なサンプリング方法を使用しています。これは効果的ですが、柔軟性に欠けます。さらに、逆プロセスの前半部分が後半部分よりも重要であることを観察しています。したがって、私たちは時間ステップのシーケンスで異なるサンプリングストライドを使用するピースワイズサンプリング方法を提案します。また、進化アルゴリズムを使用して最適なサンプリングシーケンスを見つけるための検索方法を提案します。詳細は以下に示します: 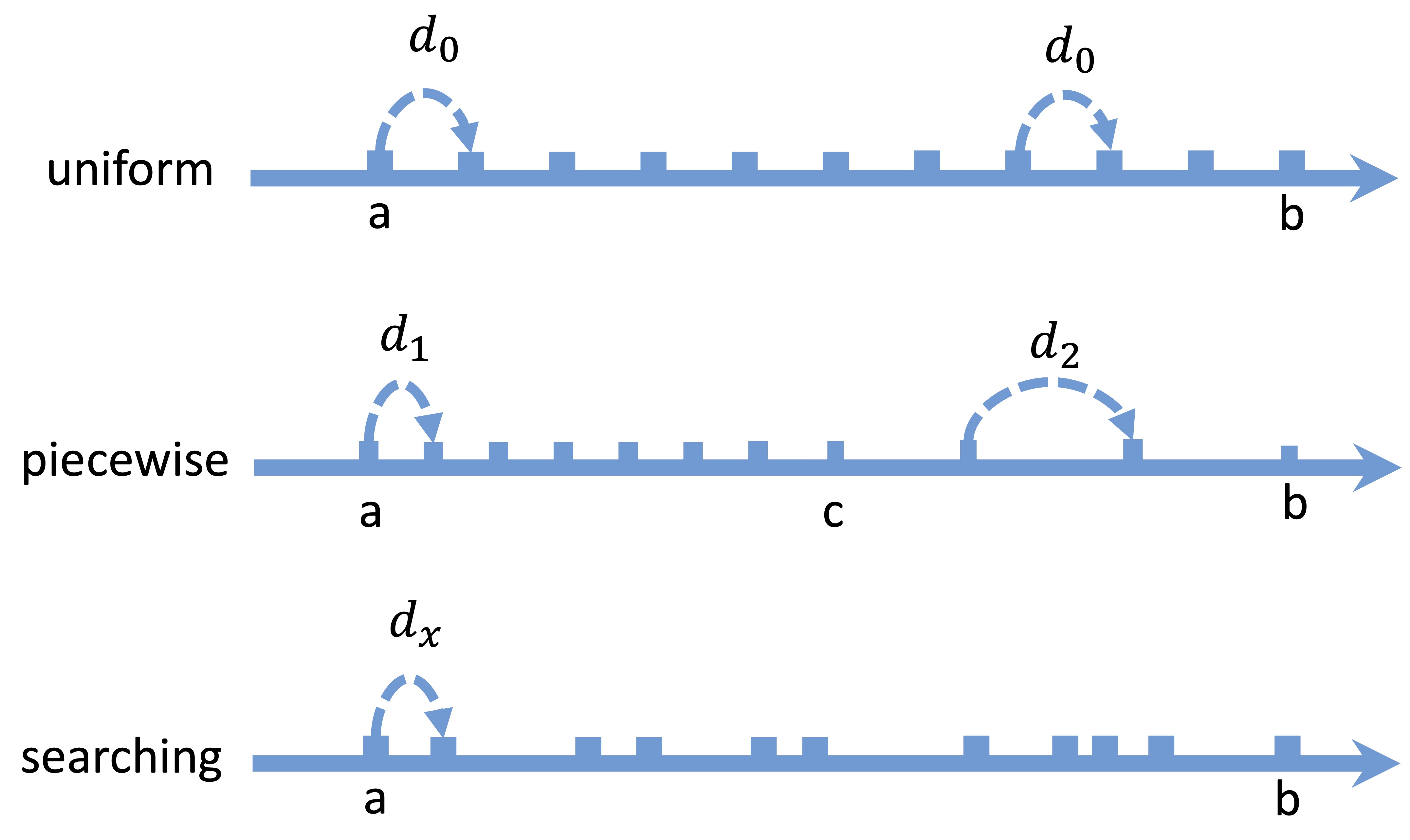
以下の図は、提案手法と他の最先端のアプローチとの視覚的比較を示しています。私たちの手法によるカラー補正の能力が優れていることに注目してください。たとえば、Ucolorは水中画像の緑のノイズをある程度除去できますが、その向上画像は元の対象の色を復元できません。Ushapeによる向上画像でも同様の現象が見られます。2行目の向上画像ではUshapeによって赤みが生じますが、私たちの手法ではそのような効果はありません。以前の方法と比較して視覚的な検査から、提案手法がカラー補正と復元において競争力のある性能を達成していることが確認されています。 
Resources
Data: GoogleDrive(pre-trained model) Publications
|
| Computer Vision and Graphics Laboratory |