| ACT2G: Attention-based Contrastive Learning for Text-to-Gesture Generation |
近年、仮想空間でのコミュニケーションが活発化し、アバターの活用が進んでいる。また、遠隔操作ロボットやコミュニケーションロボットが普及し、広く開発されている。ジェスチャーは情報伝達において重要な役割を果たすことが分かっているが、アバターやロボットのジェスチャーを自動生成することは依然課題となっている。従来の手法では、発話とジェスチャーの意味情報の関係性を学習することが難しく、発話内容の意味を適切に反映させることは非常に困難であった。そこで、本手法では意味情報を明示的に考慮するAttention-based Contrastive Learning for Text-to-Gesture (ACT2G)を提案する。
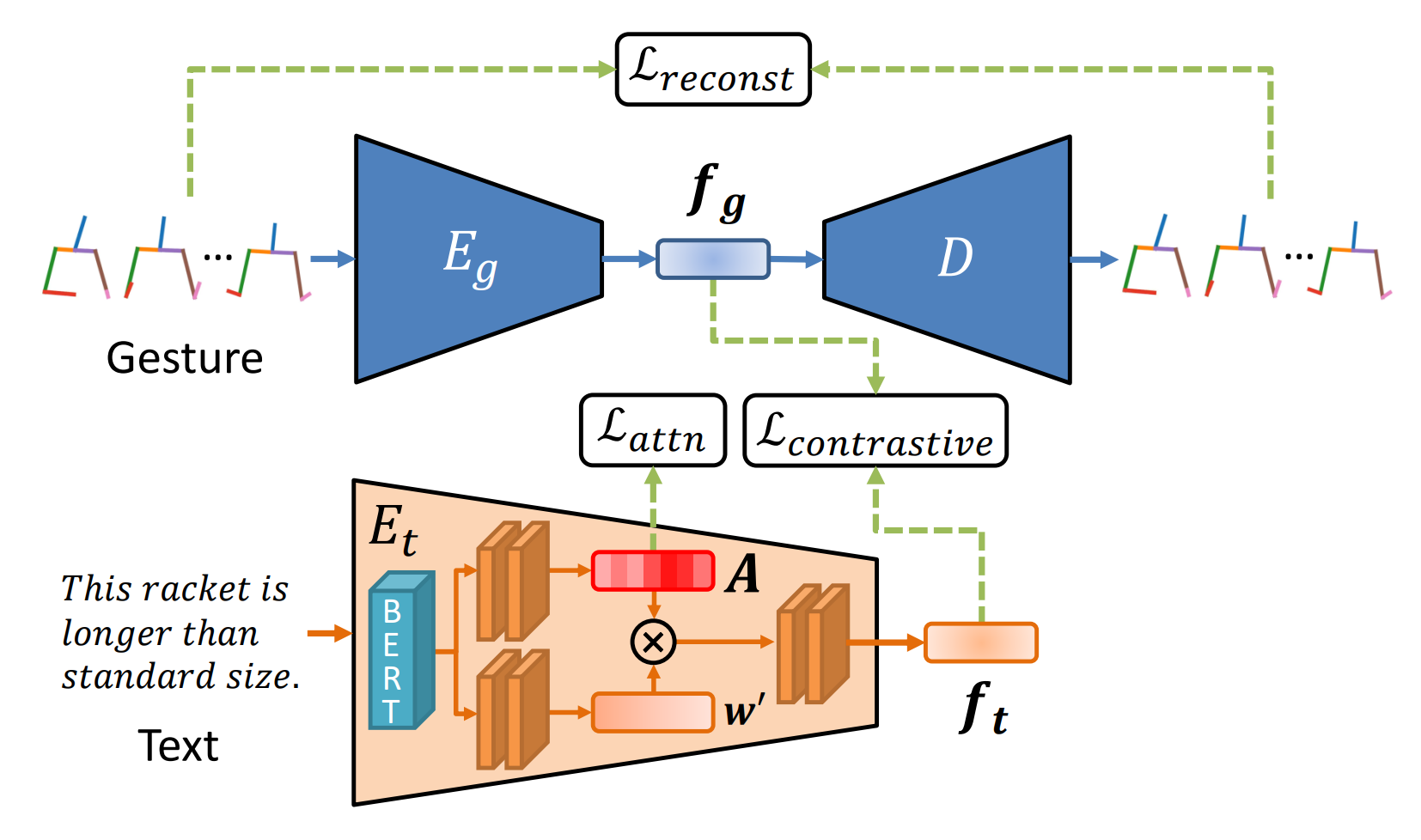
近年のデータ駆動型手法は、入力(テキスト、音声、話者ID等)と出力(ジェスチャー)を一対一で対応付けるアプローチを取っている。しかし、ジェスチャーは多様であり、同じジェスチャーが同じテキストに現れるとは限らず、学習データの不整合は学習の妨げとなる。そこで、ジェスチャーとテキストの一対多対応を実現するために、あらかじめジェスチャーをVAEから抽出した特徴でクラスタリングしておく。このクラスタリング結果は全体のネットワークを学習する際に、Contrastive Lossの計算に利用される。 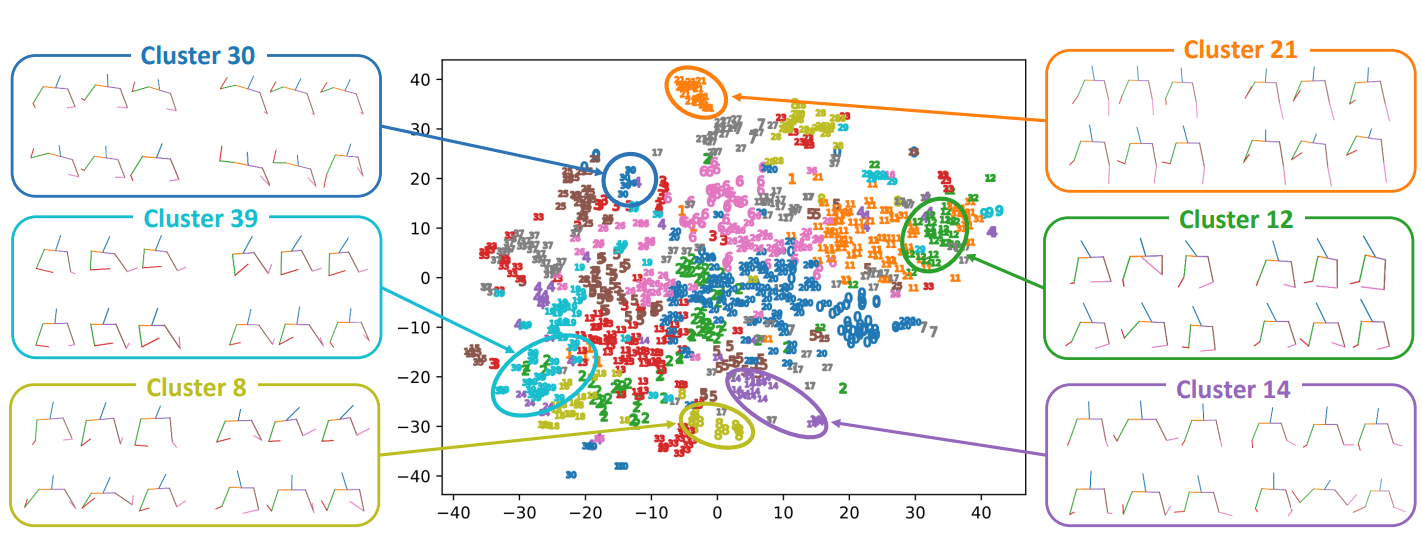
手動でジェスチャーをデザインするには専門的な知識が必要で非常に手間がかかるため、AIを使ったジェスチャー生成によりこのタスクを簡素化する。しかし、従来のアプローチでは、ユーザがデザインしたいジェスチャーを反映することはできない。そこで本手法では、ジェスチャーで表現される可能性の高い単語に着目してジェスチャーを生成する手法を提案する。TED GestureType Datasetには、ジェスチャーを表現している単語が注釈付けられている。このデータを用いて、注目すべき単語の重みを表すAttention Weightを推定し、入力テキストをエンコードする。 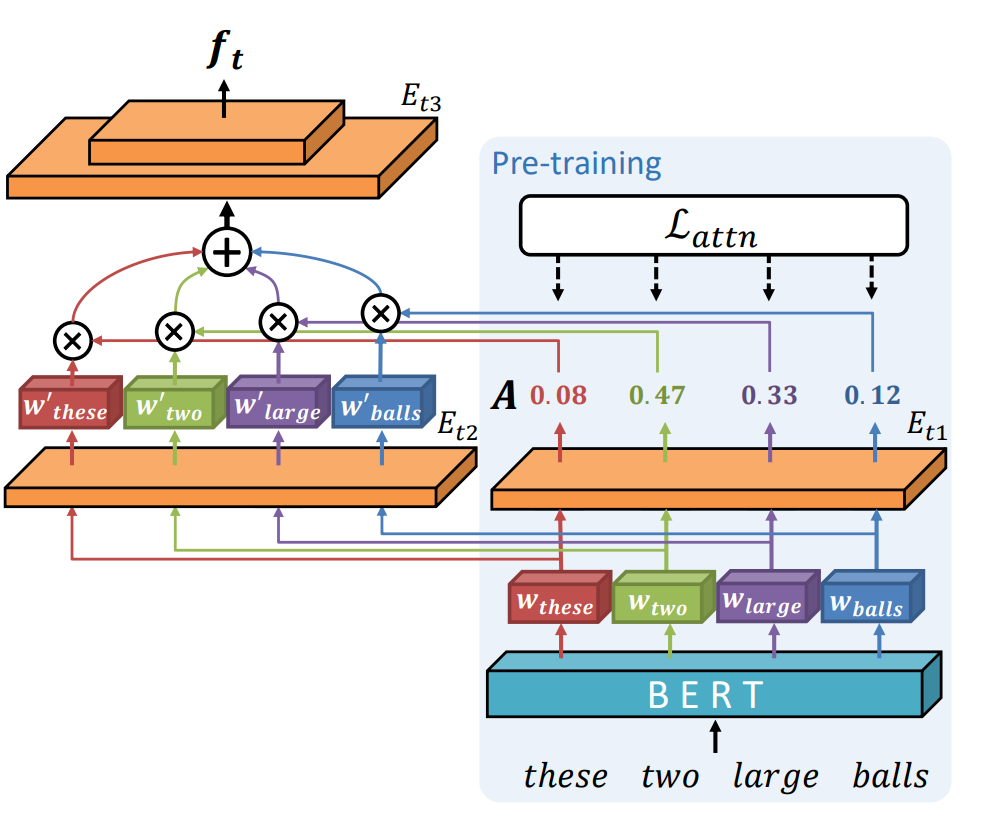
実際に生成されたジェスチャーが下図の様子である。テキストの内容を反映したジェスチャーが現れた部分を色付きの四角で囲んであり、本手法で生成されたジェスチャーは"loud"や"a lot of"の時に両腕を広げたり、"right here"と言う時に右腕を広げたりするジェスチャーが見られる。実験では100人以上の被験者を対象にユーザ評価を行い、元のジェスチャーと既存手法により生成されたジェスチャーとの比較を行った。実験の結果、本手法で生成されたジェスチャーはP値<0.01で他の3つの既存手法を有意に上回った。 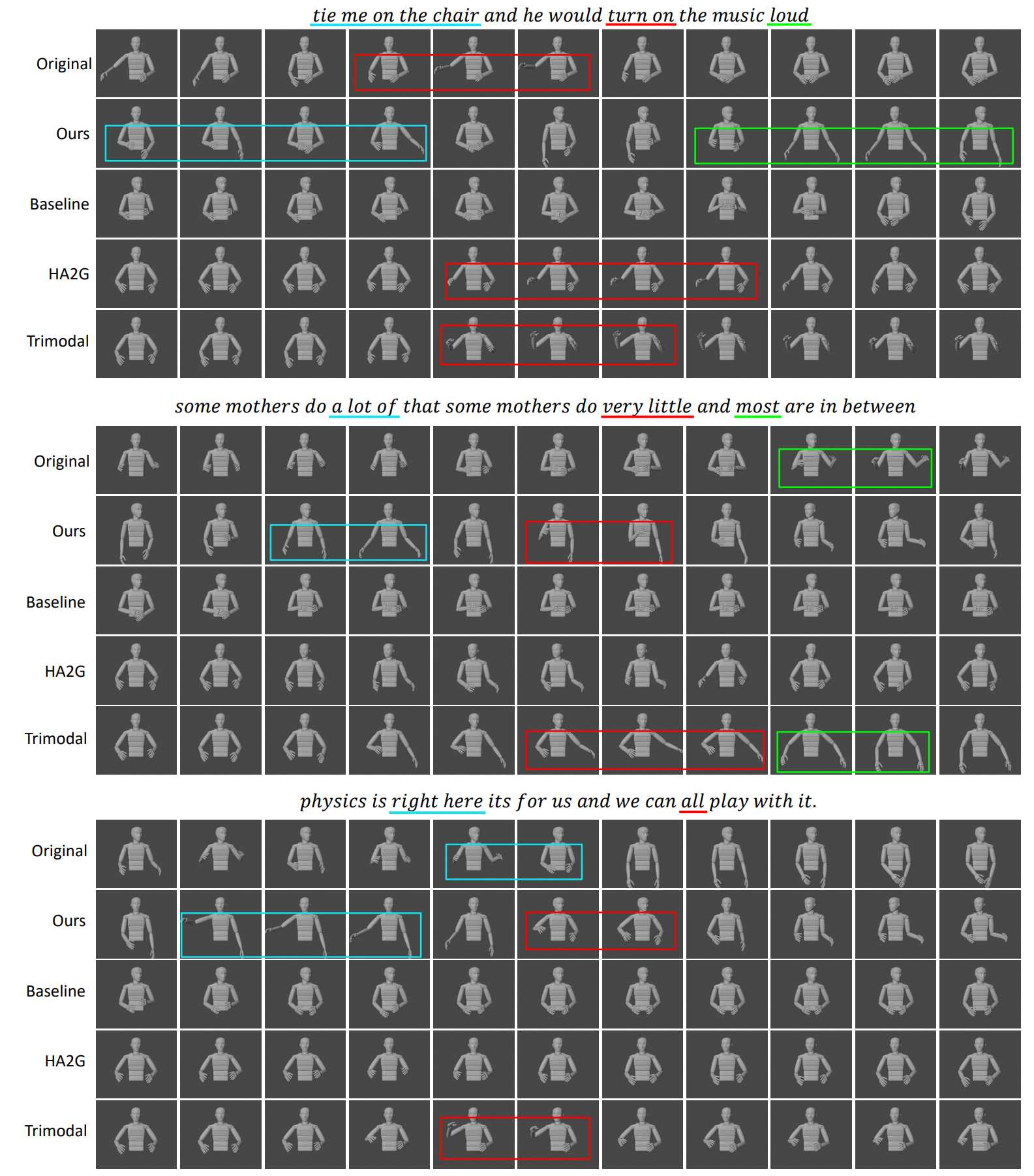
Resources
Publications
|
| Computer Vision and Graphics Laboratory |